머신러닝: 데이터를 인간이 전처리, 스스로 데이터 특징을 추출할 수 없음
딥러닝: 인간이 하던 작업을 컴퓨터가 스스로 분석 후 답을 찾음

| 구분 | 머신러닝 | 딥러닝 |
| 동작 원리 | 입력 데이터에 알고리즘 적용해 예측 수행 | 신경망으로 데이터 특징 및 관계 해석 |
| 재사용 | 동일한 유형의 데이터 분석 위한 재사용 불가능 | 동일한 유형의 데이터 분석 시 재사용 |
| 데이터 | 일반적으로 수천 개의 데이터 필요 | 수백만 개 이상의 데이터 필요 |
| 훈련 시간 | 짧음 | 김 |
| 결과 | 점수 또는 분류 등 숫자 값 | 출력은 점수, 텍스트, 소리 아무거나 가능 |
✔️ 특성 추출(feature extraction): 컴퓨터가 입력받은 데이터를 분석해 일정한 패턴이나 규칙을 찾아내기 위해 사람이 인지하는 데이터를 컴퓨터가 인지할 수 있는 데이터로 변환해줄 때 데이터별로 어떤 특징을 가지고 있는지 찾아내고 이걸로 데이터를 벡터로 변환하는 작업
머신러닝의 주요 구성 요소
- 데이터: 학습 모델 만들 때 사용
- 모델: 머신 러닝 학습 단계에서 얻은 최종 결과물
- e.g. 입력 데이터의 패턴은 A와 같다 라는 "가정"이 모델
- 학습 절차
- 모델(또는 가설) 선택
- 모델 학습 및 평가
- 평가를 바탕으로 모델 업데이트
✔️ 훈련, 검증, 테스트
- 검증 데이터셋을 사용하는 이유: 모델 성능 평가를 위해서
- 훈련 데이터셋으로 모델 학습 후 모델이 잘 예측하는지 성능 평가 위해 사용
- 검증은 훈련 데이터셋의 일부를 떼어 사용하므로 훈련 데이터셋이 많지 않다면 검증은 안하는 것이 좋다.
딥러닝 모델의 학습 과정
- 데이터 준비
- 파이토치나 케라스에서 제공하는 데이터셋 사용
- 케글이나 국내외 공개 데이터 사용
- 모델 정의: 모델(모형) 정의 단계에서 신경망을 생성
- 일반적으로 은닉층 개수 많을수록 성능이 좋아지지만, 과적합 가능성 높음
- 모델 컴파일: 활성화 함수, 손실 함수, 옵티마이저 선택
- 훈련데이터 연속형: MSE
- 이진분류: 크로스 엔트로피(cross entropy)
- 모델 훈련: 한 번에 처리할 데이터양 지정
- 너무 많으면 학습 속도 느려지고 메모리 부족 문제 발생 -> 적절한 데이터 선택하기
- 배치(훈련 데이터셋에서 일정한 묶음으로 나누어 처리하는 것)와 에포크(훈련 횟수) 선택이 중요
- 값의 변화를 시각적으로 확인하면서 파라미터와 하이퍼파라미터에 대한 최적의 값을 찾는다.
- 모델 예측: 검증 데이터셋을 적용해 실제로 예측해보기
- 예측력이 낮으면 파라미터 튜닝하거나 신경망 자체 재설계
➡️ 훈련 데이터셋 1000개에 대한 배치 크기가 20이면 샘플 단위 20마다 모델 가중치를 한 번씩 업데이트하므로 총 50번의 가중치가 업데이트된다.
📍 성능이 좋다 = 예측을 잘한다 = 훈련 속도가 빠르다
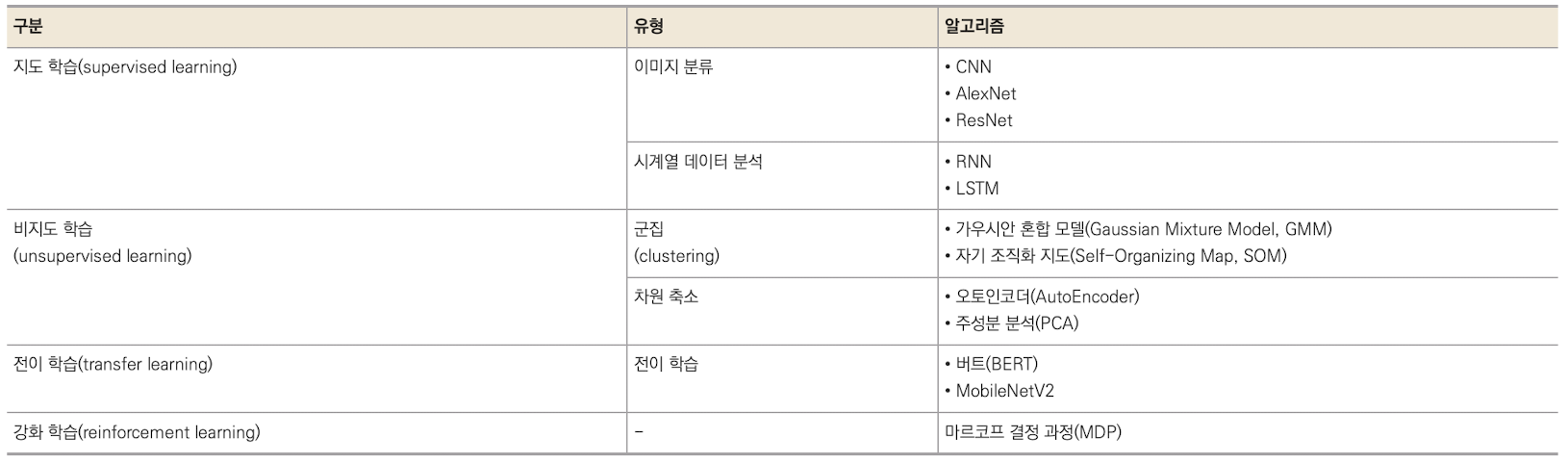
딥러닝 학습 알고리즘
지도 학습
- 컴퓨터 비전: 합성곱 신경망(CNN)
- 시계열 데이터 분류: 순환 신경망(RNN)
- 역전파 과정에서의 기울기 소멸 문제 ➡️ gate를 3개 추가해 LSTM(Long Short-Term Memory) 추가
비지도 학습
- 워드 임베딩: 자연어 ➡️ 컴퓨터가 이해할 수 있도록 단어를 벡터로 표현
- Word2Vec, GloVe를 가장 많이 사용
- 군집
- 아무런 정보가 없는 상태에서 비슷한 것들끼리 클러스터로 분류
- 머신러닝 군집만 사용하지 말고 딥러닝 군집이랑 같이 사용해 성능을 높이는 것이 좋다
- 신경망에서 군집 알고리즘 사용하기
전이학습(transfer learning)
사전에 학습이 완료된 모델로 원하는 학습에 미세 조정 기법을 이용해 학습시키는 방법
- 사전 학습 모델: 풀고자 하는 문제와 비슷하면서 많은 데이터로 이미 학습이 되어 있는 모델
- 특성 추출과 미세 조정 기법 사용