
다음 단어 예측이 ChatGPT로 이어지기까지의 핵심 단계
LLM의 기본이 되는 딥러닝과 언어 모델링
언어 모델이 chatGPT같은 대화 모델이 되기까지의 과정
LLM 활용 기술
1.1 딥러닝과 언어 모델링
딥러닝
- 인간의 두뇌에 영감 받아 만들어진 신경망으로서, 데이터 패턴을 학습하는 머신러닝의 한 분야
- 정형 데이터 (표 형태) + 비정형 데이터 (텍스트, 이미지) 뛰어난 패턴 인식 성능
LLM
- LLM은 딥러닝 기반의 언어 모델
- 자연어 처리 분야 중 자연어 생성에 속함
- 자연어 처리 : 사람의 언어를 컴퓨터가 이해하고 생성할 수 있도록 연구
- 자연어 생성 : 사람과 비슷하게 텍스트를 생성하는 방법을 연구
- 언어 모델 : 다음에 올 단어를 예측하며 문장 만들어 가는 방식으로 텍스트 생성
딥러닝 기반의 언어 모델의 중요한 3가지 사건
- 2013 워드투벡(word2vec) : 단어를 의미를 담아 숫자로 표현
- 2017 트랜스포머 아키텍쳐(transformer architecture) : 기계 번역 성능 높이기 위해 개발
- 2018 OpenAI의 트랜스포머 아키텍쳐 활용한 GPT-1 개발
1.1.1 데이터의 특징을 스스로 추출하는 딥러닝
딥러닝이 문제를 해결하는 방법
- 문제의 유형에 따라 일반적으로 사용되는 모델 준비 (자연어 처리, 이미지 처리 등)
- 풀고자 하는 문제에 대한 학습 데이터 준비
- 학습 데이터를 반복적으로 모델에 입력
➡️ 단순한 접근 방식으로 비정형 데이터 문제를 쉽게 풀 수 있다.
📍 딥러닝과 머신러닝의 가장 큰 차이 = 데이터의 피처 뽑기
- 머신러닝 : 데이터의 특징을 사람이 찾고 모델에 입력으로 넣어 결과 출력
- 데이터의 특징 : e.g. 일반적인 자동차가 갖고 있는 성질 (문이 있고, 창문이 있고,,)
- 딥러닝 : 모델이 스스로 데이터 특징을 찾고 분류하는 모든 과정 학습
1.1.2 임베딩 : 딥러닝 모델이 데이터를 표현하는 방식
데이터의 의미와 특징을 포착해 숫자로 표현
MBTI 검사로 사람을 4개의 숫자로 표현하는 것처럼 데이터를 그 의미를 담아 숫자의 집합으로 표현
데이터 사이의 거리를 계산하고 거리를 바탕으로 관련 있는 데이터와 관련 없는 데이터 구분 가능
- 검색 및 추천 : 검색어와 관련 있는 상품 추천
- 클러스터링 및 분류 : 유사하고 관련있는 데이터 하나로 묶기
- 이상치 탐지 : 나머지 데이터와 거리가 먼 데이터 이상치로 볼 수 있음
단어 임베딩 : 단어를 임베딩으로 변환한 것
단어는 워드투벡 모델을 통해 숫자의 집합인 임베딩으로 변환될 수 있다.

딥러닝 모델은 데이터 학습하는 과정에서 그 데이터를 가장 잘 이해할 수 있는 방식을 함께 배우는데, 데이터의 의미를 숫자로 표현한 것이 임베딩이다.
1.1.3 언어 모델링 : 딥러닝 모델의 언어 학습법
모델이 입력받은 텍스트의 다음 단어를 예측해 텍스트를 생성하는 방식
텍스트를 생성하는 모델을 학습시키는 방법 + 대량의 데이터에서 언어의 특성을 학습하는 사전 학습 과제(pre-training)
전이 학습 (transfer learning)
딥러닝 분야에서 하나의 문제를 해결하는 과정에서 얻은 지식과 정보를 다른 문제를 풀 때 사용하는 방식
- 사전 학습 : 대량의 데이터로 모델 학습
- 미세 조정 (fine-tuning) : 특정 문제 해결 위한 데이터로 추가 학습
📍 언어 모델링은 자연어 처리 분야에서 사전 학습을 위한 과제로 사용
✔️ 유방암이 양성인지 악성인지 분류 문제
: 유방암 데이터만으로 학습한 모델의 성능 < 사전 학습 모델의 일부를 가져와 활용했을때의 성능
➡️ 사전 학습에 사용한 이미지와 현재 풀고자 하는 이미지가 달라도 선이나 점 등을 파악하는 능력은 공통적으로 필요하기 때문

📌 다운스트림 (downstream) 과제 : 사전학습 모델을 미세 조정해 풀고자 하는 과제
학습 데이터가 적은 경우에 특히 유용!
머신러닝 vs 전이학습
- 머신러닝 모델 학습 : 처음부터 끝까지 해결하려는 문제의 데이터로 학습
- 딥러닝의 전이 학습 : 대량의 데이터로 학습 후 해결하려는 문제의 데이터로 추가 학습 ➡️ 두 단계로 모델 학습
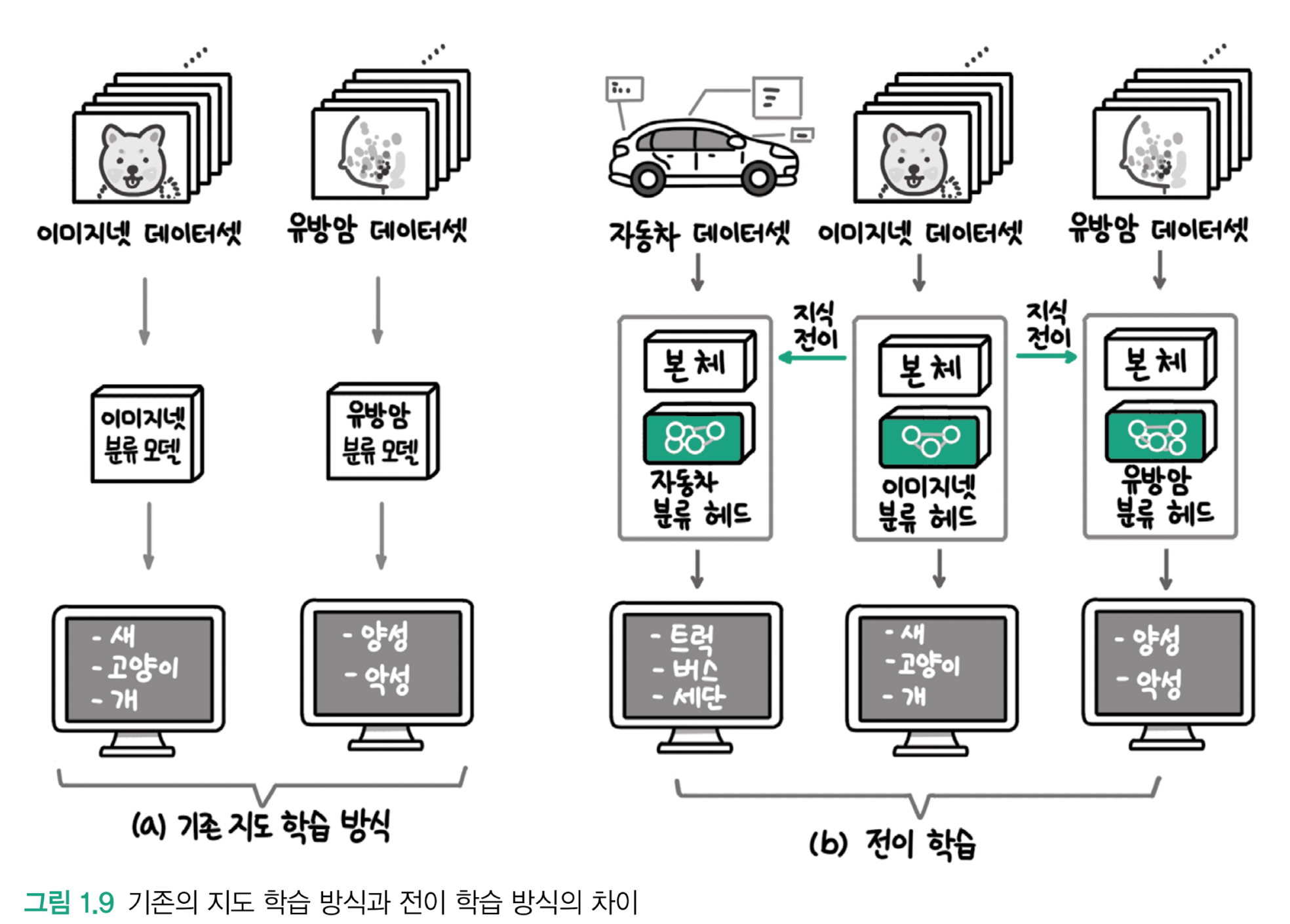
- 모델의 본체 부분 : 대규모 데이터셋인 이미지넷으로 학습한 모델을 가져온 것
- 모델의 헤드 부분 : 해결하려는 작업의 데이터셋으로 추가 학습
- 헤드 부분은 본체부분에 비해 작아서 비교적 적은 데이터로도 학습이 가능
- 헤드를 추가 학습하는 과정이 사전 학습에 비해 적은 양의 학습 데이터를 사용하므로 미세 조정이라고 함
자연어 처리 분야에서의 전이 학습
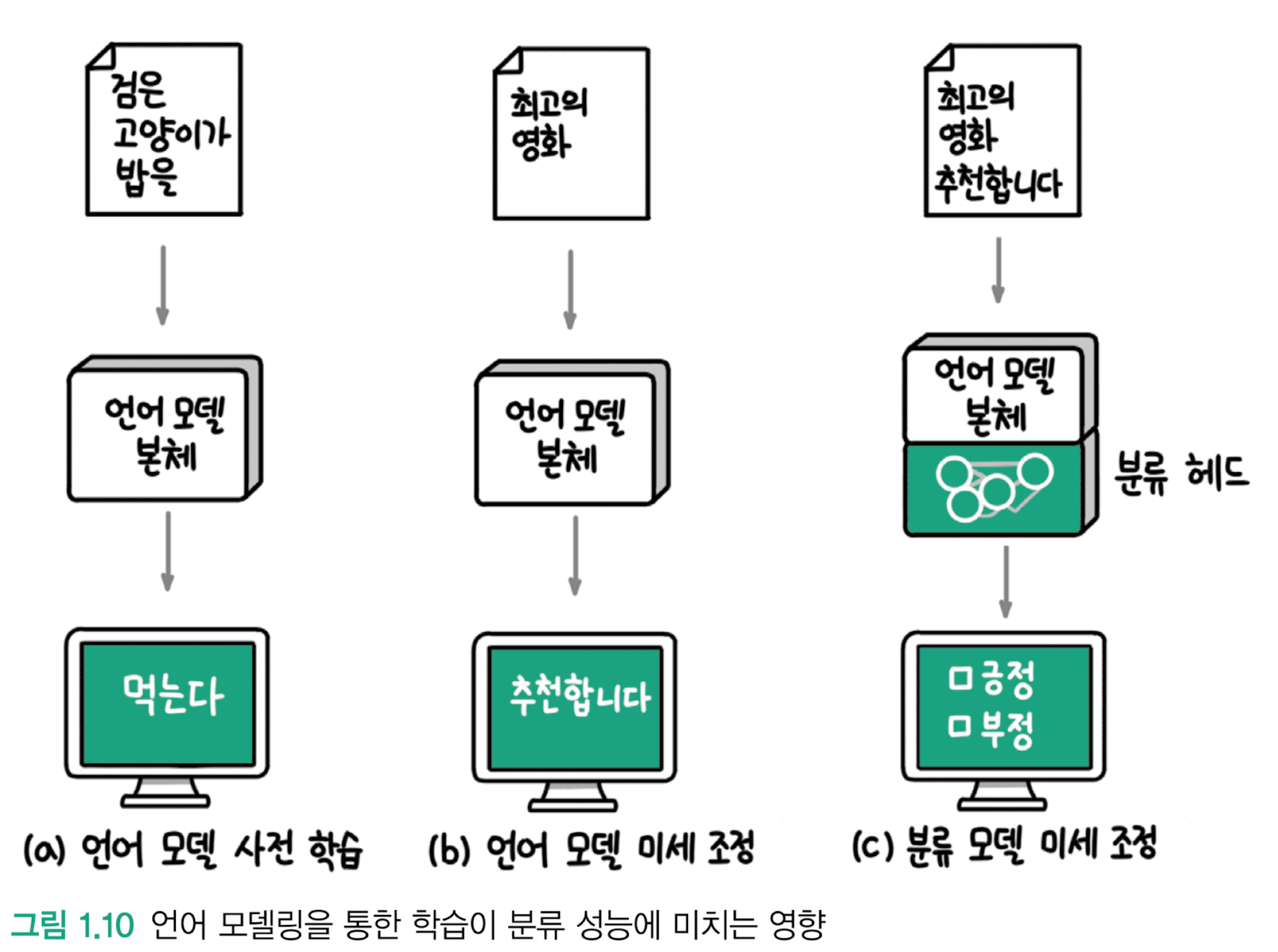
- 다음 단어를 예측하는 언어 모델링 방식으로 사전 학습 수행하면 훨씬 적은 레이블 데이터로도 기존 지도 학습 모델의 성능을 뛰어넘는다는사실 발견
- 순환신경망(RNN)에서 언어 모델링이 사전 학습 과제로 적합하다는 사실 발견
- 대표적인 트랜스포머 모델 : 구글의 BERT, OpenAI의 GPT
'AI > LLM을 활용한 실전 AI 애플리케이션 개발' 카테고리의 다른 글
| [LLM의 기초 뼈대 세우기] 02 - LLM의 중추, 트랜스포머 아키텍쳐 살펴보기 : 트랜스포머 아키텍처란(2) (1) | 2025.03.01 |
|---|---|
| [LLM의 기초 뼈대 세우기] 01 - LLM 지도 : 언어 모델이 챗GPT가 되기까지 | LLM 애플리케이션의 시대가 열리다 (0) | 2025.02.12 |
| [INTRO] (0) | 2025.02.11 |